Basics of MySQL InnoDB Cluster
- MySQL Shell
- Mysql Connector
- MySQL Router
MySQL Shell includes AdminAPI which enables you to easily configure and administer a group of at least three MySQL server instances to function as an InnoDB cluster.
Each MySQL server instance runs MySQL Group Replication, which provides the mechanism to replicate data within InnoDB clusters, with built-in failover. AdminAPI removes the need to work directly with Group Replication in InnoDB clusters.
MySQL Connectors provides driver support for connecting to MySQL from Java applications using the standard Java Database Connectivity (JDBC) API. Connector/NET enables developers to create .NET applications that connect to MySQL.
MySQL Router can automatically configure itself based on the cluster you deploy, connecting client applications transparently to the server instances. In the event of an unexpected failure of a server instance, the cluster reconfigures automatically.

Group Replication Modes
1. Single-Primary Mode
2. Multi-Primary Mode
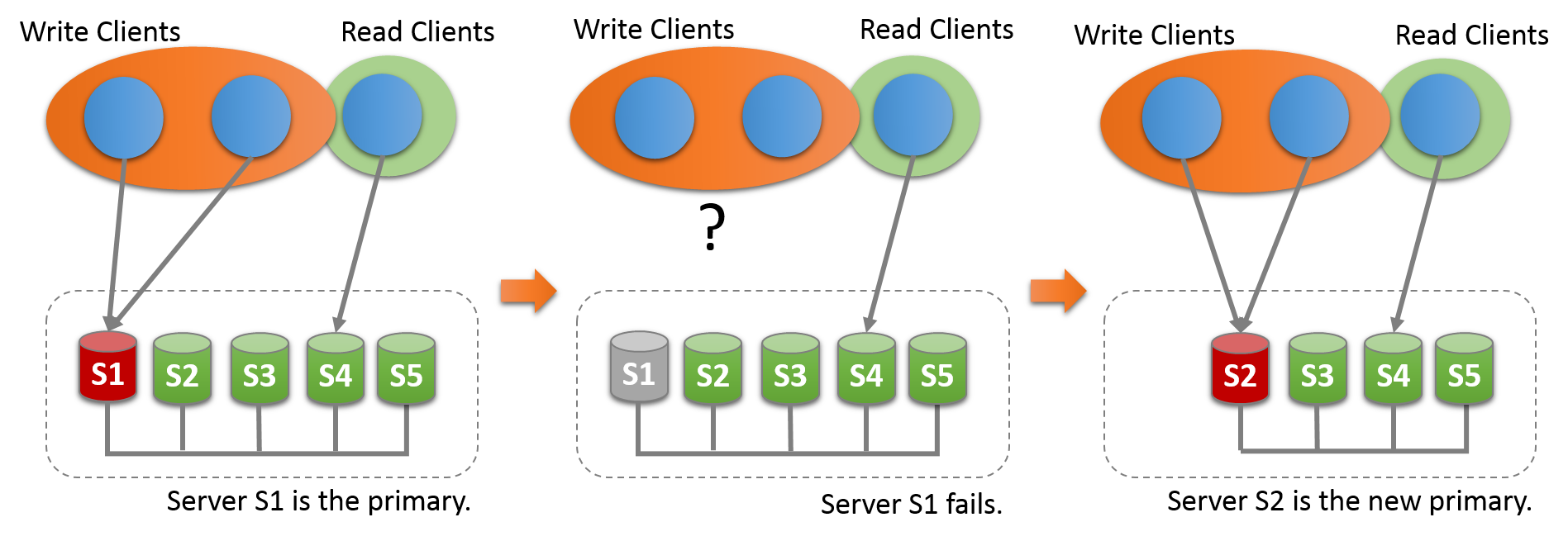
In the default single-primary mode, an InnoDB cluster has a single read-write server instance - the primary. Multiple secondary server instances are replicas of the primary. If the primary fails, a secondary is automatically promoted to the role of primary. MySQL Router detects this and forwards client applications to the new primary. Advanced users can also configure a cluster to have multiple-primaries.
Group Replication operates either in single-primary mode or in multi-primary mode.
The group's mode is a group-wide configuration setting, specified by the “group_replication_single_primary_mode” system variable, which must be the same on all members. ON means single-primary mode, which is the default mode, and OFF means multi-primary mode.
It
is not possible to have members of the group deployed in different modes, for
example one member configured in multi-primary mode while another member is in
single-primary mode.
Single-Primary Mode
In single-primary mode (group_replication_single_primary_mode=ON) the group has a single primary server that is set to read-write mode. All the other members in the group are set to read-only mode (with super-read-only=ON). The primary is typically the first server to bootstrap the group. All other servers that join the group learn about the primary server and are automatically set to read-only mode.
In single-primary mode, Group Replication enforces that only a single server writes to the group, so compared to multi-primary mode, consistency checking can be less strict and DDL statements do not need to be handled with any extra care. The option group_replication_enforce_update_everywhere_checks enables or disables strict consistency checks for a group. When deploying in single-primary mode, or changing the group to single-primary mode, this system variable must be set to OFF.
The member that is designated as the primary server can change in the following ways:
● If the existing primary leaves the group, whether voluntarily or unexpectedly, a new primary is elected automatically.
● You can appoint a specific member as the new primary using the group_replication_set_as_primary() UDF.
● If you use the group_replication_switch_to_single_primary_mode() UDF to change a group that was running in multi-primary mode to run in single-primary mode, a new primary is elected automatically, or you can appoint the new primary by specifying it with the UDF.
The UDFs can only be used when all group members are running MySQL 8.0.13 or higher. When a new primary server is elected automatically or appointed manually, it is automatically set to read-write, and the other group members remain as secondaries, and as such, read-only.

Probable issue : When a new primary is elected or appointed, it might have a backlog of changes that had been applied on the old primary but have not yet been applied on this server. In this situation, until the new primary catches up with the old primary, read-write transactions might result in conflicts and be rolled back, and read-only transactions might result in stale reads.
Solution: Group Replication's flow
control mechanism, which minimizes the difference between fast and slow
members, reduces the chances of this happening if it is activated and properly
tuned. From MySQL 8.0.14, you can also use the group_replication_consistency
system variable to configure the group's level of transaction consistency to
prevent this issue. The setting BEFORE_ON_PRIMARY_FAILOVER (or any higher
consistency level) holds new transactions on a newly elected primary until the
backlog has been applied.
Multi-Primary Mode
In multi-primary mode (group_replication_single_primary_mode=OFF) no member has a special role. Any
member that is compatible with the other group members is set to read-write
mode when joining the group, and can process write transactions, even if they
are issued concurrently.
If a member stops accepting write transactions, for example in the event of a server crash, clients connected to it can be redirected, or failed over, to any other member that is in read-write mode. Group Replication does not handle client-side failover itself, so you need to arrange this using a middleware framework such as MySQL Router 8.0, a proxy, a connector, or the application itself. Figure, “Client Failover” shows how clients can reconnect to an alternative group member if a member leaves the group.
Group Replication is an eventual consistency system. This means that as soon as the incoming traffic slows down or stops, all group members have the same data content. While traffic is flowing, transactions can be externalized on some members before the others, especially if some members have less write throughput than others, creating the possibility of stale reads.
Probable issue: In multi-primary mode, slower members can also build up an excessive backlog of transactions to certify and apply, leading to a greater risk of conflicts and certification failure.
Solution: Activate and tune Group Replication's flow control mechanism to minimize the difference between fast and slow members.From MySQL 8.0.14, if you want to have a transaction consistency guarantee for every transaction in the group, you can do this using the group_replication_consistency system variable. You can choose a setting that suits the workload of your group and your priorities for data reads and writes, taking into account the performance impact of the synchronization required to increase consistency. You can also set the system variable for individual sessions to protect particularly concurrency-sensitive transactions.
group_replication_consistency group_ also configures the fencing mechanism used by newly elected primaries in single primary groups. The effect of the variable must be considered for both read only (RO) and read write (RW) transactions. The following list shows the possible values of this variable, in order of increasing transaction consistency guarantee:
EVENTUALBoth RO and RW transactions do not wait for preceding transactions to be applied before executing. This was the behavior of Group Replication before this variable was added. A RW transaction does not wait for other members to apply a transaction. This means that a transaction could be externalized on one member before the others. This also means that in the event of a primary failover, the new primary can accept new RO and RW transactions before the previous primary transactions are all applied. RO transactions could result in outdated values, RW transactions could result in a rollback due to conflicts.
BEFORE_ON_PRIMARY_FAILOVERNew RO or RW transactions with a newly elected primary that is applying backlog from the old primary are held (not applied) until any backlog has been applied. This ensures that when a primary failover happens, intentionally or not, clients always see the latest value on the primary. This guarantees consistency, but means that clients must be able to handle the delay in the event that a backlog is being applied. Usually this delay should be minimal, but does depend on the size of the backlog.
BEFOREA RW transaction waits for all preceding transactions to complete before being applied. A RO transaction waits for all preceding transactions to complete before being executed. This ensures that this transaction reads the latest value by only affecting the latency of the transaction. This reduces the overhead of synchronization on every RW transaction, by ensuring synchronization is used only on RO transactions. This consistency level also includes the consistency guarantees provided by
BEFORE_ON_PRIMARY_FAILOVER.AFTERA RW transaction waits until its changes have been applied to all of the other members. This value has no effect on RO transactions. This mode ensures that when a transaction is committed on the local member, any subsequent transaction reads the written value or a more recent value on any group member. Use this mode with a group that is used for predominantly RO operations to ensure that applied RW transactions are applied everywhere once they commit. This could be used by your application to ensure that subsequent reads fetch the latest data which includes the latest writes. This reduces the overhead of synchronization on every RO transaction, by ensuring synchronization is used only on RW transactions. This consistency level also includes the consistency guarantees provided by
BEFORE_ON_PRIMARY_FAILOVER.BEFORE_AND_AFTERA RW transaction waits for 1) all preceding transactions to complete before being applied and 2) until its changes have been applied on other members. A RO transaction waits for all preceding transactions to complete before execution takes place. This consistency level also includes the consistency guarantees provided by
BEFORE_ON_PRIMARY_FAILOVER.
MySQL InnoDB cluster Routing ports
● 3306 : Mysql server instance port.
MySQL Router configuration creates TCP ports which we use to connect to the cluster. Ports for communicating with the cluster using both Classic MySQL protocol and X Protocol are created.
● 6446 - for Classic MySQL protocol read-write sessions, which MySQL Router redirects incoming connections to primary server instances.
● 6447 - for Classic MySQL protocol read-only sessions, which MySQL Router redirects incoming connections to one of the secondary server instances.
● 64460 - for X Protocol read-write sessions, which MySQL Router redirects incoming connections to primary server instances.
● 64470 - for X Protocol read-only sessions, which MySQL Router redirects incoming connections to one of the secondary server instances
Group Membership
In MySQL Group Replication, a set of servers forms a replication group. A group has a name, which takes the form of a UUID. The group is dynamic and servers
can leave (either voluntarily or involuntarily) and join it at any time. The
group adjusts itself whenever servers join or leave.
If a server joins the group, it automatically brings itself up to date by fetching the missing state from an existing server. If a server leaves the group, for instance it was taken down for maintenance, the remaining servers notice that it has left and reconfigure the group automatically.
Group Replication has a group membership service that defines which servers are online and participating in the group. The list of online servers is referred to as a view. Every server in the group has a consistent view of which servers are the members participating actively in the group at a given moment in time.
Failure Detection
Group Replication includes a failure detection mechanism that is able to find and report which servers are silent and as such assumed to be dead. At a high level, the failure detector is a distributed service that provides information about which servers may be dead (suspicions). Suspicions are triggered when servers go mute. When server A does not receive messages from server B during a given period, a timeout occurs and a suspicion is raised. Later if the group agrees that the suspicions are probably true, then the group decides that a given server has indeed failed. This means that the remaining members in the group take a coordinated decision to exclude a given member.
If a server gets isolated from the rest of the group, then it suspects that all others have failed. Being unable to secure agreement with the group (as it cannot secure a quorum), its suspicion does not have consequences. When a server is isolated from the group in this way, it is unable to execute any local transactions.
1)MySQL InnoDB Cluster node Addition Issue: - Cluster.addInstance: : MySQL server has gone away (RuntimeError)
2)Install & Configure MySQL Router - MySQL InnoDB Cluster

Comments
Post a Comment
Please do not enter any spam link in comment Section suggestions are Always Appreciated. Thanks.. !